
You are here
Data, what data?
The definition most often used to define research data is the OECD’s (2007):
“Factual records (numerical scores, textual records, images and sounds) used as primary sources for scientific research and that are commonly accepted, in the scientific community, as necessary to validate research findings. A research dataset constitutes a systematic, partial representation of the subject being investigated.”
Research data can take different forms (numerical data, text, sound, image, survey questionnaire, software…) and can come from different sources, which entail different methods of storage. Here, data are divided into 4 types:
- Observation data such as temperature or rainfall readings, remote sensing data, photos of an event or else survey data. They are unique and impossible to reproduce, hence the need to store them indefinitely.
- Experimental data, such as those generated by laboratory equipment or machine performance measurements. These data are supposed to be reproducible, but it is difficult to replicate the same experimental conditions or replicating the process can be so expensive as to be prohibitive. It is therefore recommended that data collected in such situations should be carefully archived.
- Numerical simulation data produced by software, for example in climate or economic modelling. These data are reproducible and, while it is not necessary to store all of them, it is essential to describe the model and the associated software, and to store all the information that can be used to rerun the model.
- Derived or compiled data such as those obtained by searching texts or a database. These are raw data that have undergone successive processing and analysis. It is highly recommended that they should be stored carefully.
- Software: the stakes related to Open Data, dissemination platforms or legal background make it similar to data in this context.
|
|
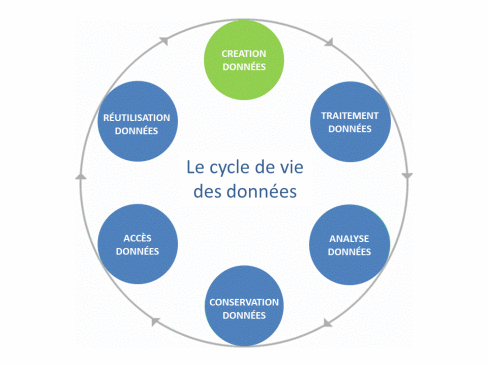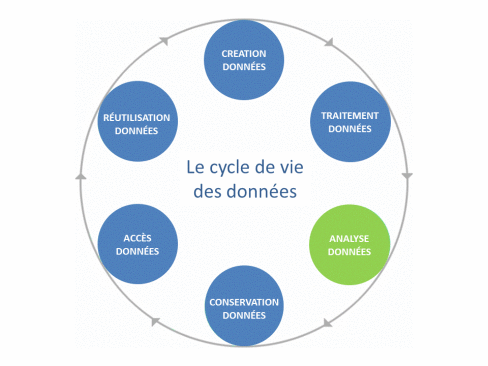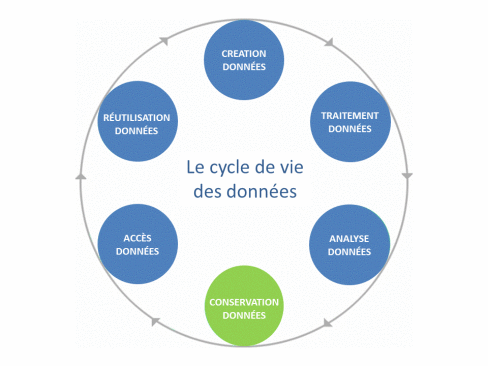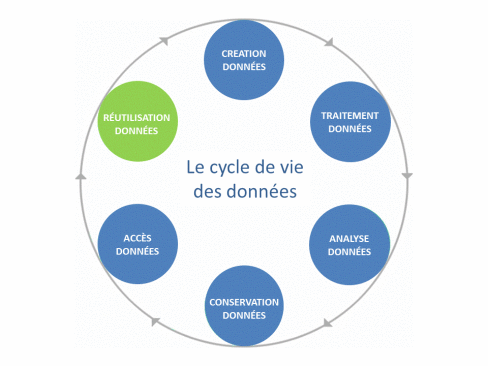
So a dataset can be defined as the aggregation, in readable form, of raw or derived data that possess a certain “unity” (Gaillard R., 2014). Finally, all stages from the creation to the use of data, including processing, analysis, storage and dissemination, constitute the life cycle of the data.
The Scholarly Communication Unit helps researchers to manage the data produced during a research project intelligently and to share and disseminate them as effectively as possible.
Why manage and share your data?
There are many good reasons for publishing one’s data:
|
|
- REPLICABILITY – results can be reproduced and validated, enhancing the quality of science;
- RESPONSIBLE USE OF PUBLIC FUNDS – avoid repeating what has already been demonstrated;
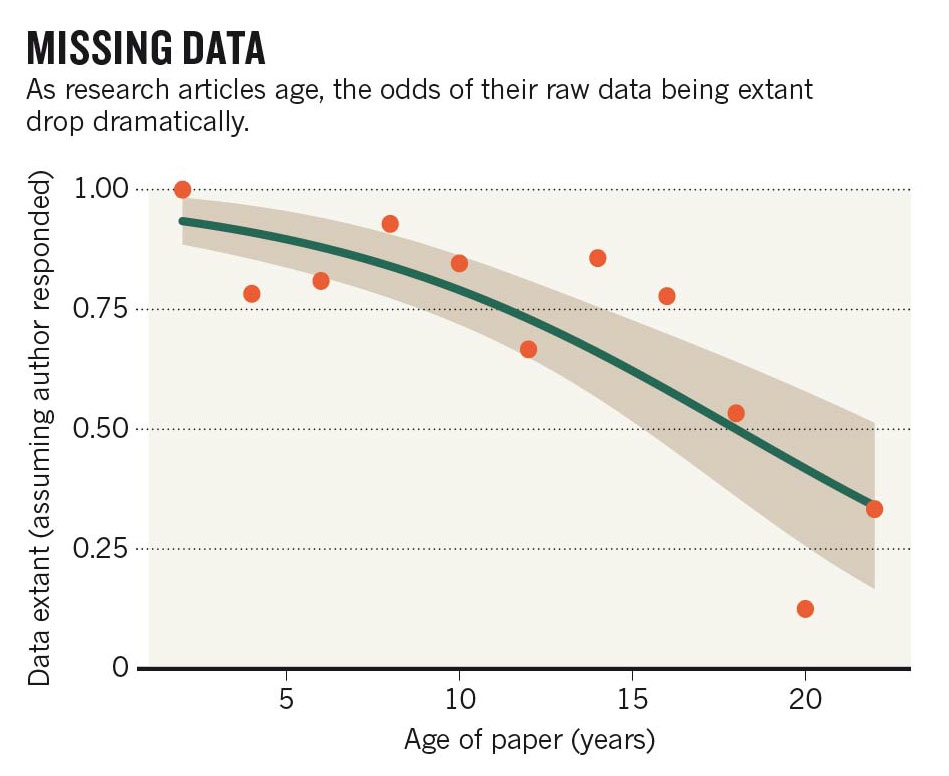
- PRESERVATION – in order to easily retrieve its data (sometimes even one’s own data); we have all heard stories of data on a USB drive being lost because coffee was spilt on it or it was left behind in a move. This problem of negligence with data is old news in academic circles, but not all researchers are yet aware of it or know what to do about it. A 2013 study showed that the availability of data in scientific articles plummets over time, falling to just 20% for articles published 20 years ago. (NB: the dataset for this study is available via the Dryad repository.)
- INNOVATION – to foster the creation of new knowledge;
- COLLABORATION – to trigger collaborations;
- REPUTATION – to raise one’s profile, to support a funding application, CV content. A study has shown that the number of times an article gets cited increases if the associated data are available. Moreover, the CNRS Ethics Committee issued the following recommendation in 2015: “The work of making usable data available from raw data should be recognized in assessment and promotion decisions regarding the staff involved in these tasks.”
See also “Research Data - 2. Legal Background”
See also "Research Data - 3. Technical questions"
The Scholarly Communication unit is constantly looking to learn more about this subject, but your community must also have information and standard practices. Feel free to contact us so we can find out how best to support you.
As you know, we enjoy a challenge!!
We are data librarians !