
Vous êtes ici
Des données, quelles données ?
La définition la plus communément utilisée pour définir les données de la recherche (ou data research) est celle de l’OCDE (2007) :
« Enregistrements factuels (chiffres, textes, images, sons) utilisés comme source principale pour la recherche scientifique et généralement reconnus par la communauté scientifique comme nécessaires pour valider les résultats de la recherche. Un ensemble de données de recherche constitue une représentation systématique et partielle du sujet faisant l’objet de la recherche ».
Les données de la recherche peuvent revêtir des formes différentes (données chiffrées, texte, son, image, questionnaire d’enquête, logiciel…) et elles peuvent provenir de sources différentes impliquant un mode d’archivage différent ; on distingue alors 5 types de données :
- les données d’observation comme des relevés de température ou de précipitations, les données de télédétection, les photos d’un événement ou encore les données d’enquêtes. Elles sont uniques et impossibles à reproduire d’où la nécessité de les conserver indéfiniment.
- les données expérimentales comme celles générées par un équipement en laboratoire ou les mesures de performance d’une machine. Ces données sont supposées être reproductibles mais il peut être difficile de reproduire les mêmes conditions de l’expérience ou reproduire la manipulation peut être tellement coûteux que cela en devient prohibitif. Par conséquent, il est recommandé d’archiver avec soin les données recueillies dans de telles situations.
- les données de simulation numérique produites par des logiciels comme pour des modèles climatiques ou économiques. Ces données sont reproductibles et s’il n’est pas nécessaire d’archiver toutes les données ainsi produites, il est en revanche indispensable de décrire le modèle, le logiciel associé et d’en archiver toutes les informations qui permettront sa ré-exploitation.
- les données dérivées ou compilées comme celles obtenues par de la fouille de textes ou de données d’une base. Il s’agit de données brutes qui ont fait l’objet de traitements et d’analyses successifs. Il est fortement recommandé de les archiver avec soin.
- le code informatique : les enjeux liés à l'Open Data, aux infrastructures de diffusion ou au contexte juridique le rapprochent des données.
|
|
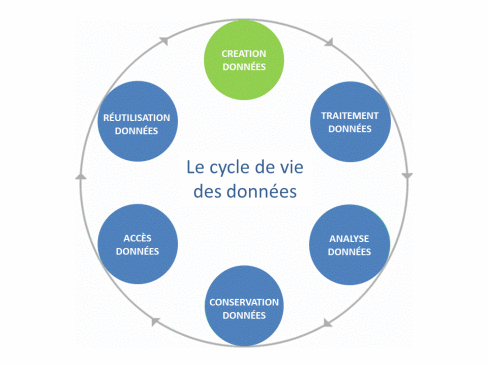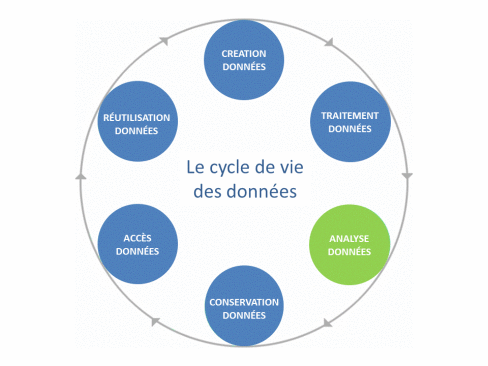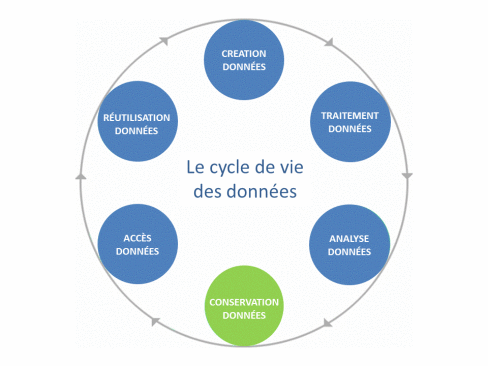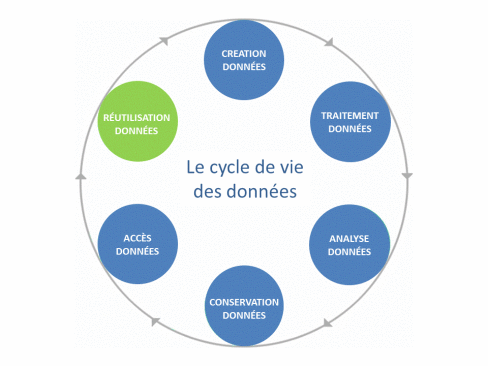
En conséquence, un jeu de données (ou dataset) peut alors être défini comme l’agrégation, sous une forme lisible, de données brutes ou dérivées présentant une certaine « unité » (Gaillard R., 2014). Enfin toutes les étapes de la création à la réutilisation des données, en passant par leur traitement, leur analyse, leur conservation et leur mise à disposition constituent le cycle de vie des données.
Le Pôle IST soutient les chercheurs dans la mise en place d’une gestion raisonnée des données produites dans le cadre d’un projet de recherche et les guide pour un partage et une valorisation optimale.
Pourquoi gérer et partager ses données ?
Il existe un grand nombre de bonnes raisons de publier ses données :
|
|
- RÉPLICABILITÉ - permettre la reproduction et la validation des résultats et ainsi améliorer la qualité de la science,
- UTILISATION CITOYENNE DES FONDS PUBLICS - éviter de refaire ce qui a déjà été validé,
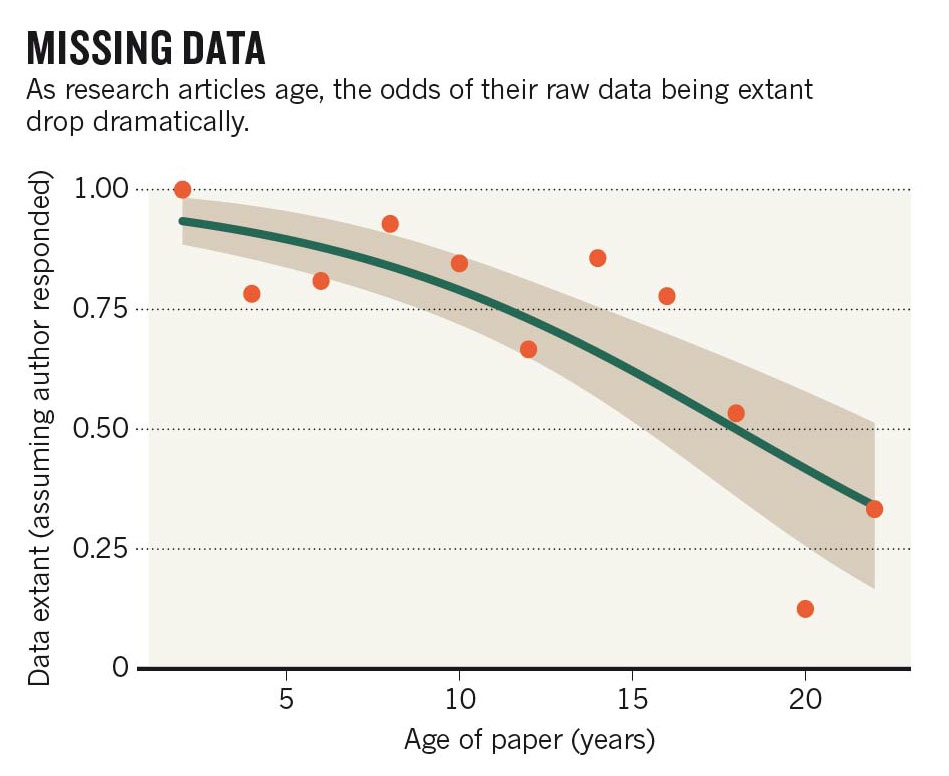
- PRESERVATION - pour retrouver facilement les données (parfois même les siennes) ; on connaît tous des histoires de données perdues car stockées sur une clé USB inondée de café ou abandonnée dans un carton lors d’un déménagement. Ce problème de négligence vis-à-vis des données est soulevé depuis longtemps dans le milieu académique mais tous les chercheurs n’en sont pas encore conscients ou ne savent pas comment y remédier. Une étude a montré en 2013 que la disponibilité des données d’articles scientifiques diminuait de façon vertigineuse au fil du temps jusqu’à atteindre seulement 20% pour les articles publiés il y a 20 ans. A noter que le dataset pour cette étude est disponible via l’entrepôt Dryad.
- INNOVATION - pour permettre la création de nouvelles connaissances,
- COLLABORATION - pour déclencher des collaborations,
- VALORISATION - pour augmenter sa visibilité, pour étayer une demande de financement, son CV. Une étude a montré que le nombre de citations d’un papier augmentait si les données associées étaient disponibles. Par ailleurs, le COMETS du CNRS a émis la préconisation suivante en 2015 : « Le travail de mise à disposition de données utilisables à partir de données brutes doit être reconnu dans l'évaluation et les décisions de promotion des personnels qui s’y impliquent. »
Voir aussi "Données de la recherche - 2. Contexte juridique"
Voir aussi "Données de la recherche - 3. Aspects techniques"
Le Pôle IST se forme et s’informe tous les jours sur ce sujet mais des informations et des habitudes doivent aussi exister dans votre communauté. N’hésitez pas à nous solliciter pour que l’on définisse ensemble à quels niveaux nous pouvons être un soutien pour vous.
Vous le savez, nous aimons les défis !!
We are data librarians !