
You are here
Data Management Plan
|
© European Union, 2016 |
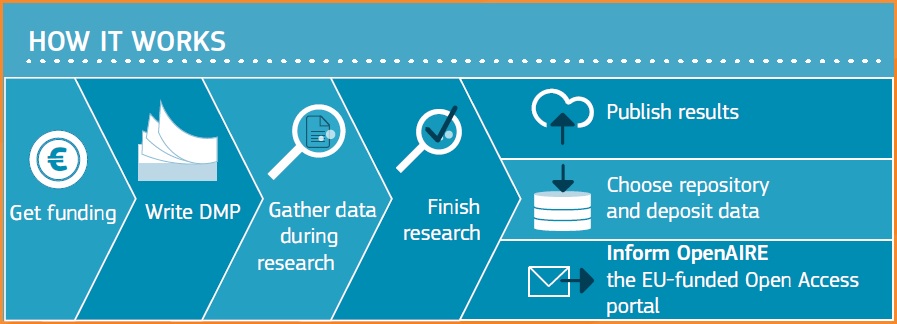
The Data Management Plan (DMP) is a document drawn up right at the beginning of a project to define each team member’s role and responsibilities with regard to data management and to identify what types of data will be produced or collected, what can be shared, from what date, and under what conditions. This document is not fixed and needs to be regularly updated as the project progresses.
It is also a way to define certain technical aspects and to apply the so-called FAIR principles (Findability, Accessibility, Interoperability, Reusability):
- conversion of data to open format in order to facilitate reuse,
- naming convention for files and folders,
- storage space consistent with the estimated volume,
- secure and effective backup throughout the project and beyond,
- document describing the data (code list or manual).
Sharing your data does not mean making them available everywhere in the world and immediately. As we saw earlier with the EU’s motto “As open as possible, as closed as necessary”, the aim is to make them available to as many people as possible so that science is shared, while keeping within the legal, ethical and contractual framework of the project.
It should be noted that for a H2020 project, the DMP is a deliverable that must be included in the project submission and supplied in its first version within the first 6 months.
There are support tools for drafting a DMP, such as DMP OPIDoR (a tool developed from DMPOnline), which is available to the higher education and research community. It includes the DMP template recommended for european or ANR projects. You can create an account using your @enpc.fr credentials.
For more information, follow the 8 multimedia tutorials produced by INIST-CNRS. Above all though, don’t hesitate to ask us for help. We have had the training and we need practice!
Where to publish?
The most apparently simple and most common way of sharing data is to include them directly with the supplementary materials (also called the supporting information or additional content) in the publication they relate to. These supplementary materials may consist of tables, photos or figures, sometimes combined with information about methodology. Of course, this is a worthwhile first effort at sharing, but it raises several problems: these include long-term conservation, the fact that it is often impossible to identify these data independently of the publication, and finally issues with yielding rights to the publisher of the journal. Moreover, access to these data depends on the conditions of access to the journal, which may be protected by a paywall.
It is preferable to place your data in a data repository and apply a license that defines the possibilities of use (See : Which license). Since the Loi pour une République Numérique (Digital Republic Act) provides that data should be freely reusable, even for commercial purposes, there is no point choosing a license that is too restrictive.
There are large numbers of repositories of different types:
- institutional repositories (Harvard Dataverse, Sextant for IFREMER, INRA Dataverse, IrsteaData),
- discipline-based or thematic repositories like Pangaea or EarthChem or Materials Data Facility,
- multidisciplinary repositories like Figshare, Mendeley Data, Zenodo (developed as part of the European OpenAire project), Dryad or Nakala (structure for the social sciences, set up by the Huma-Num facility). HAL also belongs to this category, but for certain types of data only, and given that it is not what the international community uses and that HAL does not assign a DOI (Digital Object Identifier), it would seem preferable to choose a dedicated data repository.
The repositories are described by standardized metadata, which make data easy to find and to cite provided that they are assigned a DOI.
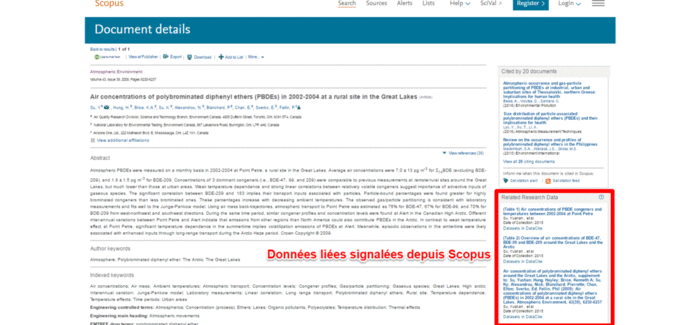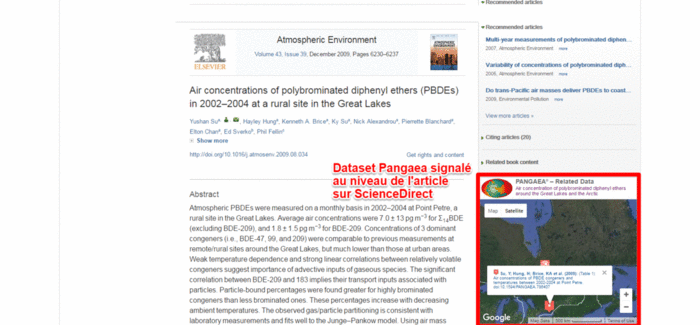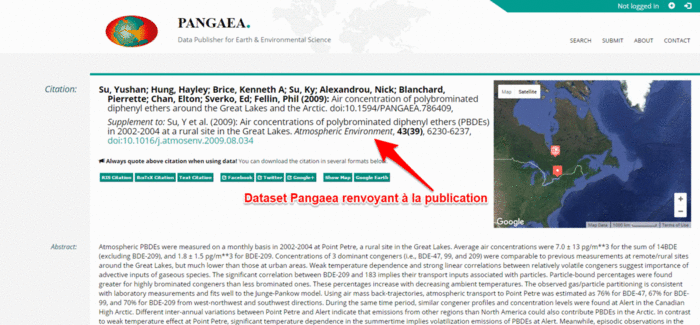
With the DOI of the publication or publications that use a dataset and the DOI of the dataset itself, a lasting two-way link is created; this is used, for example, in ScienceDirect, which displays an interactive map with the location of the data associated with an article when they are uploaded to the Pangaea repository. The same link is also specified in Scopus in the Related Research Data insert. Look at this sample publication (10.1016/j.atmosenv.2009.08.034) in Scopus, in ScienceDirect, and the related data.
Finally, to highlight a dataset, its producer can publish a data paper (or software paper for software), which describes the data, and the method used to produce or collect them. Publishing this data paper (subject to the standard peer review process) is a way to inform the community of the existence of the dataset, to facilitate its reuse, and possibly to generate citations, notably once a DOI is assigned. The data paper generates recognition for the work done by the researchers who produced the data. Have a look at this example or this one.
How to choose?
There are search engines for repositories (like re3data.org) and datasets (DataOne, DataCite, DataSearch, Google Dataset Search). This is the best way to find where your community shares its data.
In order to guide researchers in their choice of a trusted repository, there is a certificate called the CoreTrust Seal that repositories can request to certify that they meet certain quality criteria for storage, integrity and methods of making data available, and you can use their selection criteria as a checklist.
However, to make your task easier, we have produced a dynamic table that will help you easily identify the sites that match your needs.
This table includes data repositories, journals that publish data papers or data papers among other items, search engines, but also electronic laboratory notebook tools. The lab notebook is where the first data or the first information on data are recorded, so it is never too soon to think about them…
Click to access the dynamic table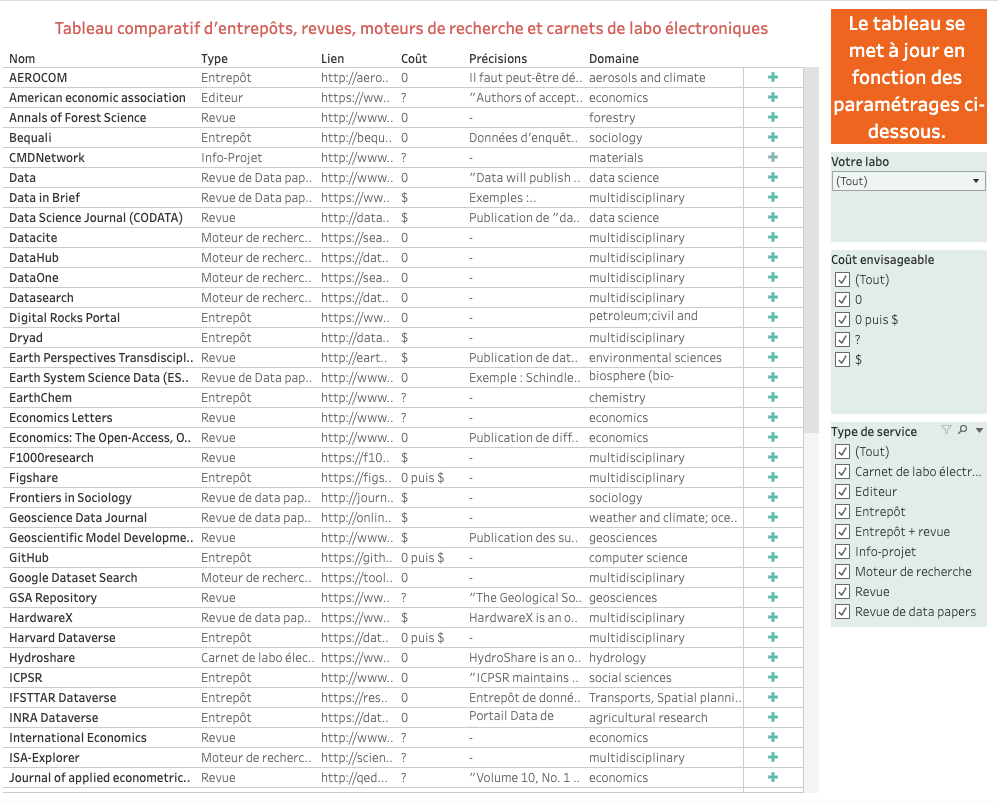
See also “Research Data - 1. Introduction”
See also "Research Data - 2. Legal background"
The Scholarly Communication unit (Pôle IST) is constantly looking to learn more about this subject, but your community must also have information and standard practices. Feel free to contact us so we can find out how best to support you.