
Vous êtes ici
Plan de Gestion de Données
|
© European Union, 2016 |
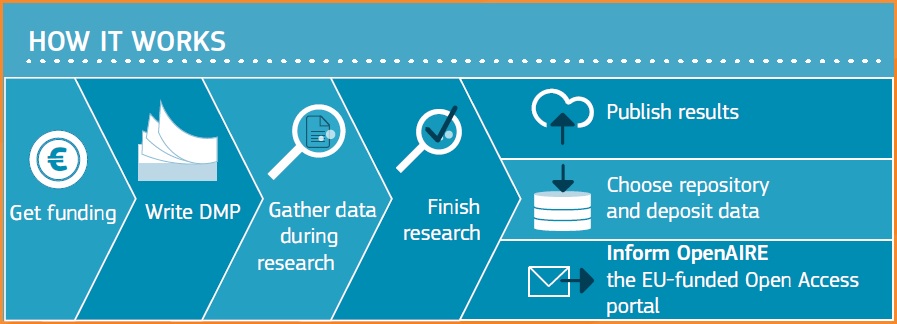
Le Plan de Gestion de Données ou DMP (Data Management Plan) est un document élaboré au tout début du projet pour définir le rôle et la responsabilité de chacun dans la gestion des données et pour identifier de quels types seront les données produites ou collectées, lesquelles pourront être partagées, à partir de quand, et selon quelles conditions. Ce document n’est pas figé et devra être mis à jour régulièrement au fil du projet.
C’est aussi le moyen de définir certains aspects techniques et d’appliquer les principes FAIR (Findability, Accessibility, Interoperability, Reusability) :
- conversion des données produites afin de les mettre à disposition dans un format ouvert pour faciliter leur réutilisation,
- convention de nommage des fichiers et répertoires,
- stockage en cohésion avec la volumétrie estimée,
- sauvegarde sécurisée et efficace tout au long du projet et après,
- documentation décrivant les données (nomenclature ou manuel de codes).
Partager ses données n’implique pas de diffuser toutes ses données dans le monde entier et sans délai. Comme nous l’avons vu plus haut avec la punchline de l’UE « As open as possible, as closed as necessary », il s’agit de les rendre disponibles au plus grand nombre pour le partage de la science tout en respectant le cadre juridique, éthique et contractuel du projet.
À noter que pour un projet H2020, le DMP est un livrable qui doit être inscrit lors de la soumission du projet et fourni dans sa première version dans les 6 premiers mois.
Il existe des outils pour aider à la rédaction d’un DMP comme par exemple DMP OPIDoR (outil développé sur la base de l’outil DMPOnline) mis à disposition de la communauté ESR pour aider à la rédaction du DMP. Il intègre le modèle de DMP préconisé pour un projet ANR ou un projet européen. Vous pouvez vous créer un compte à partir de vos identifiants @enpc.fr.
Pour plus d’informations, consultez les 8 tutoriels multimédia réalisés par l’INIST-CNRS et surtout, n’hésitez pas à nous demander de l’aide, nous nous sommes formés et avons besoin de pratiquer !
Où publier ?
Le moyen le plus simple en apparence et le plus fréquent de partage des données consiste à les intégrer directement à la publication qu’elles alimentent avec des supplementary materials (aussi appelés supporting information ou additional content) ; il s’agit par exemple de tableaux, de photos ou de figures, accompagnés parfois d'éléments d’informations méthodologiques. C’est évidemment un premier effort louable de partage mais on identifie cependant plusieurs problèmes concernant la conservation à long terme, ou encore l’impossibilité fréquente de pouvoir identifier ces données indépendamment de la publication et enfin les problèmes de droits cédés à l’éditeur de la revue. Par ailleurs, l’accès à ces données dépend des conditions d’accès à la revue et peut donc être bloqué par un abonnement payant.
Il est préférable de déposer ses données dans un entrepôt de données (data repository) et d’y appliquer une licence définissant ainsi les possibilités d’usage (Voir : Quelle licence appliquer). Comme la Loi pour une République Numérique prévoit que les données soient librement réutilisables, même de façon commerciale, inutile de choisir une licence trop restrictive.
Il existe un grand nombre d’entrepôts de différents types :
- entrepôts institutionnels (Harvard Dataverse, Sextant pour l’IFREMER, INRA Dataverse, IrsteaData),
- entrepôts disciplinaires ou thématiques comme Pangaea ou EarthChem ou Materials Data Facility),
- entrepôts multi-disciplinaires comme Figshare, Mendeley Data, Zenodo (développé dans le cadre du projet européen OpenAire), Dryad ou Nakala (structure pour les SHS, mise en place par la TGIR Huma-Num). HAL entre aussi dans cette catégorie mais pour certains types de données seulement et dans la mesure où ce n’est pas ce que la communauté internationale utilise et que HAL n’attribue pas de DOI, il semble préférable de choisir un entrepôt dédié aux données.
Les dépôts sont décrits par des métadonnées standardisées, cela permet de rendre les données facilement repérables et citables dans la mesure où un DOI leur est attribué.
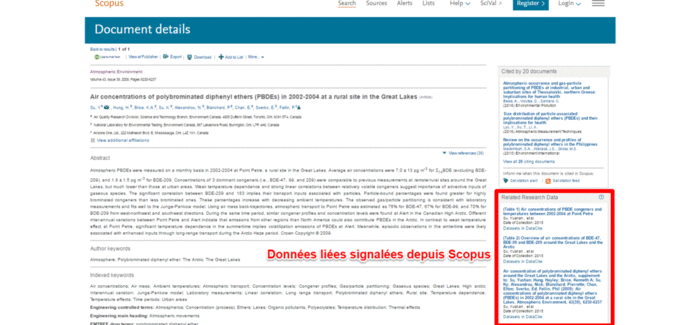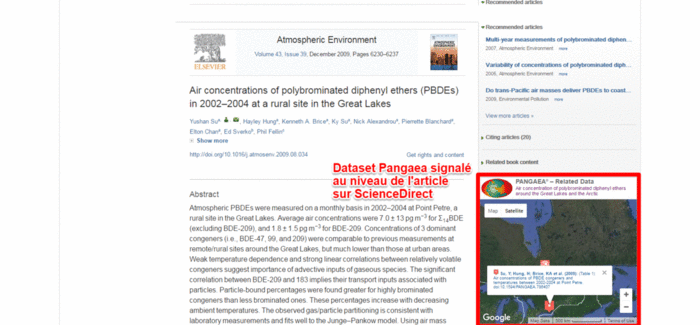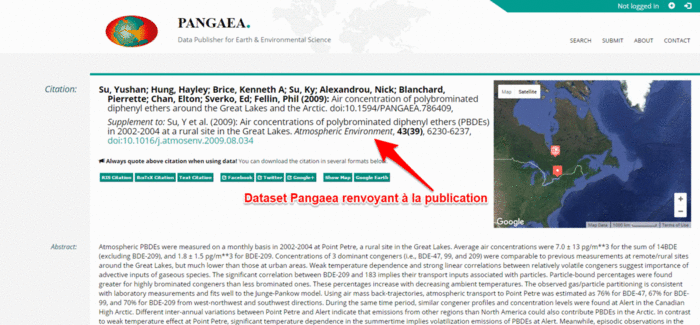
Grâce au DOI de la ou des publications qui exploitent un dataset et à celui du dataset lui-même, un lien bidirectionnel pérenne est ainsi créé ; il est par exemple exploité dans ScienceDirect qui affiche une carte interactive avec la localisation des données associées à un article lorsqu’elles sont déposées dans l’entrepôt Pangaea. Ce même lien est aussi signalé dans Scopus dans l’encart Related Research Data. Voir cet exemple de publication (10.1016/j.atmosenv.2009.08.034) dans Scopus, dans ScienceDirect et les données liées) :
Enfin, pour une meilleure valorisation d’un jeu de données, son producteur pourra publier un data paper (ou software paper pour un logiciel). L’objectif est de décrire les données, comment elles ont été produites ou collectées. La publication de ce data paper (soumise au processus classique de peer-reviewing) permettra d’informer la communauté de l’existence du dataset, d’en faciliter la réutilisation et pourra faire l’objet de citations notamment grâce à l’identifiant DOI qu’il aura reçu. Le data paper permet la reconnaissance du travail réalisé par les chercheurs qui ont produit les données. Voir cet exemple ou celui-ci.
Comment choisir ?
Il existe des moteurs de recherche d’entrepôts (comme re3data.org) et de jeux de données (DataOne, DataCite, DataSearch, Google Dataset Search). C’est le meilleur moyen pour repérer où votre communauté partage ses données.
Afin de guider le chercheur dans le choix d’un entrepôt de confiance (trusted repository), il existe une certification appelée CoreTrust Seal qui a entrepris de certifier à la demande les entrepôts répondant à des critères de qualité concernant le stockage, l’intégrité et les modalités de mise à disposition des données et vous pouvez utiliser leurs critères de sélection comme une checklist.
Mais pour vous faciliter la tâche, nous avons réalisé un tableau dynamique qui vous permettra d’identifier facilement les sites qui correspondent à vos besoins.
Ce tableau présente des entrepôts de données, des revues de data papers ou des revues publiant entre autres des data papers, des moteurs de recherche mais aussi des outils de carnets de laboratoire électroniques. C’est dans le carnet de labo que les premières données ou les premières informations sur les données sont notées et qu’il faut donc commencer à y prêter attention...
Cliquez pour accéder au tableau dynamique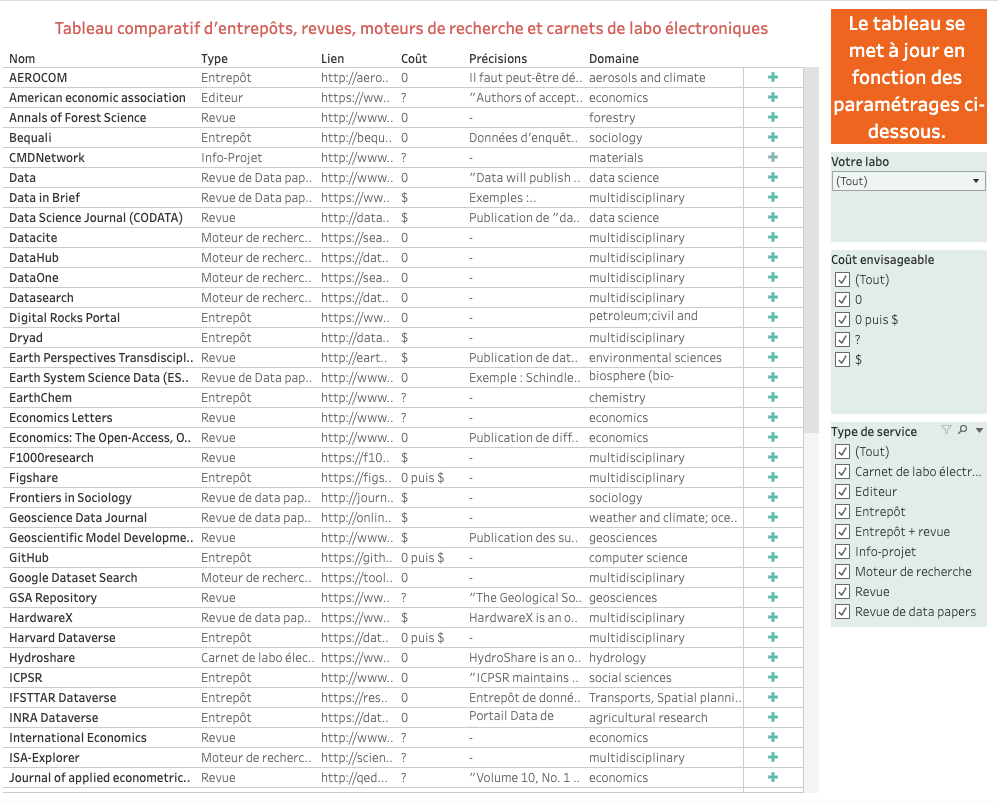
Voir aussi "Données de la recherche - 1. Introduction"
Voir aussi "Données de la recherche - 2. Contexte juridique"
Le Pôle IST se forme et s’informe tous les jours sur ce sujet mais des informations et des habitudes doivent aussi exister dans votre communauté. N’hésitez pas à nous solliciter pour que l’on définisse ensemble à quels niveaux nous pouvons être un soutien pour vous.